
Chaos Engineering for QA Teams: Testing Resilience Before Production
In the fast-paced world of software development, ensuring system reliability is paramount. As organizations increasingly rely on distributed microservices and cloud-native architectures, the need for robust testing methodologies has never been more critical. This is where chaos engineering comes into play, offering a proactive approach to identifying vulnerabilities before they impact end-users. In this article, we will explore the principles of chaos engineering, its benefits for QA teams, and practical strategies for implementing resilience testing effectively.
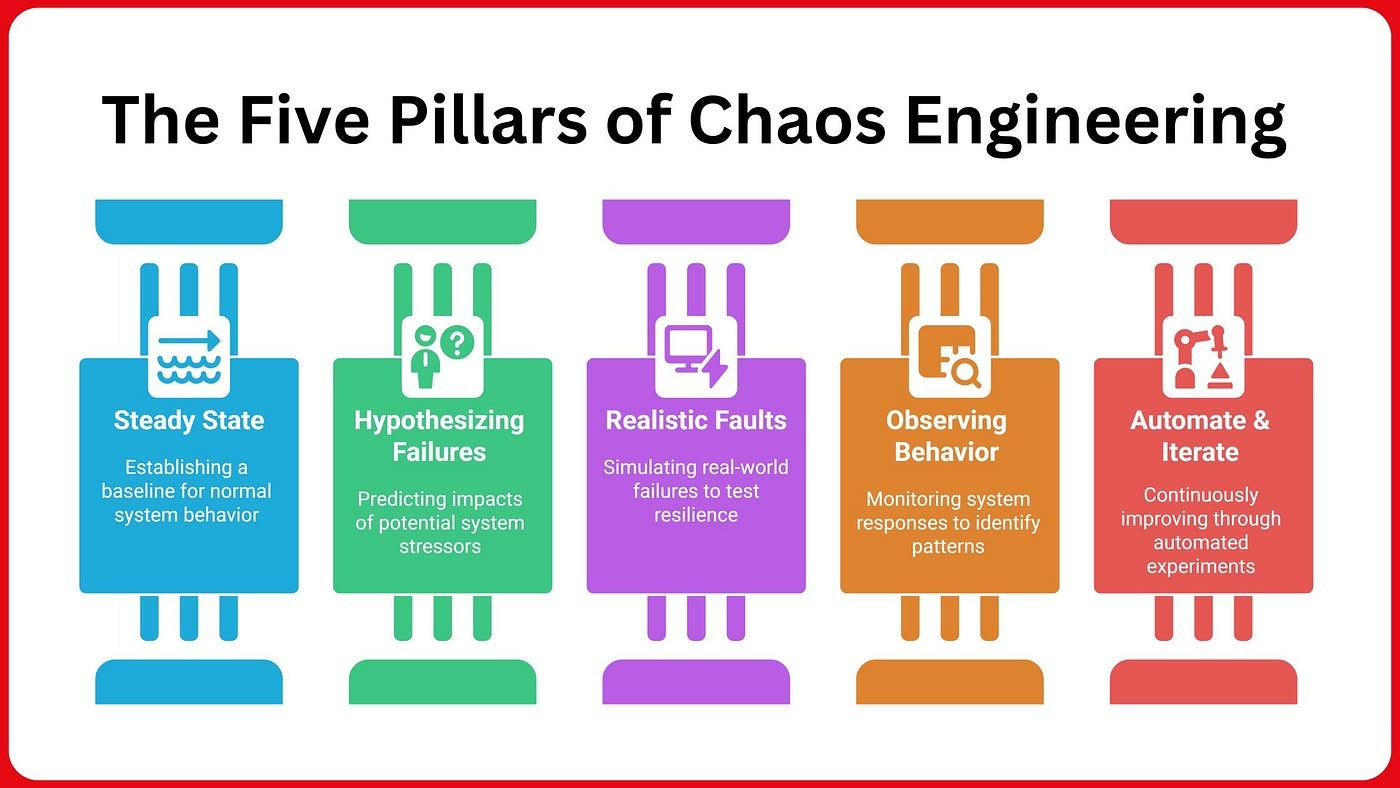
Understanding Chaos Engineering
Chaos engineering is the practice of intentionally introducing failures into a system to observe how it behaves under stress. This methodology allows teams to simulate real-world disruptions, such as server crashes or network outages, in a controlled environment. The goal is to uncover weaknesses and validate that systems can recover gracefully from unexpected failures.
The Philosophy Behind Chaos Engineering
The core philosophy of chaos engineering is simple: "Don't trust your system until you've seen it fail and recover." This mindset encourages teams to shift their focus from merely verifying functionality under ideal conditions to ensuring operational resilience. By proactively testing how systems respond to failures, organizations can build confidence in their ability to maintain service continuity.
Historical Context
The concept of chaos engineering gained traction in the early 2010s, primarily through the efforts of Netflix, which developed tools like Chaos Monkey to randomly terminate instances in production. This pioneering approach laid the foundation for chaos engineering as a formal discipline, leading to the establishment of principles and best practices that are now widely adopted across various industries.
Benefits of Chaos Engineering for QA Teams
Implementing chaos engineering offers numerous advantages for quality assurance teams, enhancing their ability to deliver reliable software.
1. Improved System Resilience
By simulating outages and disruptions, QA teams can identify weaknesses in their systems before customers encounter them. For instance, a payment gateway may pass functional tests but fail under a network partition. Chaos experiments reveal these vulnerabilities early, allowing teams to address them proactively.
2. Increased Confidence in Production
Chaos engineering provides valuable insights into how systems behave during stress. This visibility builds confidence that failover mechanisms, retries, and self-healing processes work as intended when needed most. Teams can rest assured that their systems are equipped to handle real-world challenges.
3. Reduced Downtime and Faster Recovery
Proactively addressing failure points leads to a significant reduction in Mean Time to Recovery (MTTR). By regularly conducting resilience experiments, organizations can improve their service level agreements (SLAs) and ensure business continuity, even in the face of unexpected incidents.
4. Shift-Left on Reliability
Integrating chaos engineering into the QA process allows teams to test for resilience before deployment. This shift-left approach ensures that potential issues are identified and resolved during the development cycle, rather than during incident management.
Implementing Chaos Engineering: A Step-by-Step Approach
To effectively implement chaos engineering, QA teams should follow a structured approach that includes defining hypotheses, selecting appropriate tools, and measuring outcomes.
1. Define Chaos Hypotheses
Start by formulating clear hypotheses about how the system should behave under specific failure scenarios. For example:
· What happens if our database goes down for 30 seconds?
· Can our load balancer handle 20% of nodes failing?
These hypotheses will guide the design of chaos experiments and help teams measure success.
2. Select the Right Tools
Choosing the right chaos engineering tools is crucial for effective experimentation. Some popular options include:
-
Chaos Monkey: Developed by Netflix, this tool randomly terminates instances in production to validate redundancy.
-
Simmy: Amazon's chaos tool for simulating API failures and latency injection.
-
LitmusChaos: A Kubernetes-native tool that allows for controlled pod terminations and network chaos experiments.
3. Run Experiments Safely
Always begin chaos experiments in staging or test environments before moving to controlled production tests. Define the blast radius—i.e., the scope of the experiment—and establish rollback plans to mitigate risks.
4. Measure and Analyze Outcomes
Track key metrics such as availability, error rates, latency, and recovery time during chaos experiments. Additionally, assess user impact—does the failure disrupt critical workflows like checkout or reporting? This analysis will provide valuable insights into system behavior.
5. Automate and Integrate
Integrate chaos tests into your continuous integration and continuous deployment (CI/CD) pipeline. This ensures that resilience testing becomes a continuous practice rather than a one-time activity, allowing teams to catch regressions and maintain system reliability.
Real-World Applications of Chaos Engineering
Chaos engineering is not just a theoretical concept; it has been successfully implemented by leading organizations to enhance system resilience.
Netflix: Pioneering Chaos Engineering
Netflix's Chaos Monkey is a prime example of chaos engineering in action. By randomly terminating production instances, Netflix ensures that its services are self-healing and can maintain uninterrupted streaming for users, even in the event of node failures.
Amazon: Simulating API Failures
Amazon employs Simmy to simulate API failures and high latency. This allows QA teams to test retry logic and fallback mechanisms for services that depend on external APIs, ensuring a seamless user experience during disruptions.
Kubernetes Teams: Leveraging LitmusChaos
LitmusChaos is widely used by QA and DevOps teams running Kubernetes. It enables controlled pod terminations, CPU stress tests, and network chaos experiments, ensuring that containerized applications remain robust and resilient.
Key Scenarios for Chaos Engineering in QA
Chaos engineering can be applied to various scenarios to validate system resilience effectively.
Payment System Testing
Simulate a third-party gateway timeout and verify that transactions queue gracefully and retry instead of failing silently. This ensures that users can complete their purchases without disruption.
E-commerce Checkout Flow
Introduce chaos by killing a microservice, such as the recommendation engine, and ensure that the checkout process remains unaffected. This validates the system's ability to handle dependencies gracefully.
Mobile App Backend
Inject latency into API calls and confirm that the mobile app displays a "loading" state rather than crashing. This helps maintain a positive user experience even during performance degradation.
Best Practices for Chaos Engineering
To maximize the effectiveness of chaos engineering, teams should adhere to best practices that promote safety and reliability.
1. Start Small
Begin with small-scale experiments that target specific components or services. Gradually increase the scope as confidence in the system's response grows.
2. Monitor Closely
Implement robust monitoring solutions to gain visibility into system health before, during, and after chaos experiments. This allows teams to detect issues in real-time and respond promptly.
3. Document Everything
Treat each chaos experiment as a scientific trial. Document hypotheses, test setups, and outcomes to build a knowledge base that can inform future experiments.
4. Foster a Culture of Learning
Encourage a culture of experimentation within the organization. Emphasize that chaos engineering is about learning and improving, not about assigning blame for failures.
Conclusion
Chaos engineering is a powerful methodology that empowers QA teams to build resilient systems capable of withstanding real-world disruptions. By proactively testing for vulnerabilities and validating recovery mechanisms, organizations can enhance their operational reliability and deliver exceptional user experiences. As we embrace chaos engineering, we not only safeguard our systems but also foster a culture of continuous improvement and innovation.
Incorporating chaos engineering into our QA practices is not just a trend; it is a strategic imperative for organizations aiming to thrive in today's digital landscape. By embracing this proactive approach, we can ensure that our systems are not only functional but also resilient, ready to face the challenges of an ever-evolving technological landscape.





